

Redis系统总结研究
Executive Summary
核心观点(金字塔原理)
结论先行: Redis是一个高性能的内存数据库,通过精心设计的数据结构、事件驱动模型和渐进式rehash等机制,实现了高效的数据存储与访问。
支撑论点:
- Redis采用Reactor模式处理事件,文件事件优先于时间事件,基于I/O多路复用实现高并发
- 内部数据结构经过精心优化:SDS解决C字符串缺陷、渐进式rehash保证服务可用、跳表实现有序集合
- 事务支持ACID中的一致性和隔离性,但不保证原子性和持久性;支持多种持久化模式
SWOT 分析
| 维度 | 分析 |
|---|---|
| S 优势 | 内存级读写性能、丰富的数据结构、单线程避免锁竞争、渐进式rehash保证服务不中断 |
| W 劣势 | 事务不支持回滚、内存容量受限、单线程无法利用多核CPU |
| O 机会 | 缓存加速、分布式锁、消息队列、排行榜/计数器等实时场景 |
| T 威胁 | 数据持久化存在时间窗口、大key影响性能、集群数据一致性挑战 |
适用场景
- 高频读写的缓存层,降低数据库压力
- 分布式系统中的会话管理、分布式锁
- 实时排行榜、计数器、消息队列等场景
- Redis命令参考
- Redis命令参考2
- 注意: 源码版本3.2.8
- 面试Redis
总结Redis使用以及底层实现原理
第一部分: Redis安装
//Mac 安装brew
brew install redis
redis-server
redis-cli
第二部分: Redis整体架构;
- 初始化Server相关参数设置默认值
- 读取配置文件,覆盖默认值选项
- 初始化服务器功能模块;
-
- 注册信号实践
-
- 初始化客户端链表
-
- 初始化共享对象
-
- 检测设置最大客户端连接数
-
- 初始化数据库
-
- 初始化网络连接
-
- 是否初始化AOF重写
-
- 初始化服务器实时统计数据
-
- 初始化后台计划任务
-
- 初始化慢查询日志
-
- 初始化后台线程任务
-
- 从RDB或AOF重载数据(如果开启了AOF,优先AOF恢复数据.否则从RDB恢复数据.如果恢复数据失败,则直接退出)
- 网络监听启动前的准备工作
- 进入循环开启事件监听,接受客户端请求.
事件处理 select/epoll/kqueue
事件处理概述:
- Redis采用Reactor模式来处理事件,Redis会将所有待处理的事件放入事件池,然后挨个取出其中的事件, 调用该事件的回调函数对其进行处理,这样的模式就称为Reactor模式。
- Redis的事件分为文件事件和时间事件两种。其中,文件事件采用I/O多路复用技术,监听I/O事件, 例如读、写事件等,当事件的描述符变为可读或可写时,就将该事件放入待处理事件池,Redis在事件循环的时候会对其进行一一处理。 而时间事件则是维护一个定时器,每当满足预设的时间要求,就将该时间事件标记为待处理,然后在Redis的事件循环中进行处理。 Redis对于这两种事件的处理优先级是,文件事件优先于时间事件。
- 文件事件(fileEvent):Redis通过套接字与客户端进行连接,而文件事件就是服务器对套接字操作的抽象。
- 时间事件: Redis一些操作需要在给定的事件点执行,而时间事件就是服务器对这类定时操作的抽象。
/* File event structure */
typedef struct aeFileEvent {
// 文件时间类型:AE_NONE,AE_READABLE,AE_WRITABLE
int mask; /* one of AE_(READABLE|WRITABLE) */
// 可读处理函数
aeFileProc *rfileProc;
// 可写处理函数
aeFileProc *wfileProc;
// 客户端传入的数据
void *clientData;
} aeFileEvent; //文件事件
/* Time event structure */
typedef struct aeTimeEvent {
// 时间事件的id
long long id; /* time event identifier. */
// 时间事件到达的时间的秒数
long when_sec; /* seconds */
// 时间事件到达的时间的毫秒数
long when_ms; /* milliseconds */
// 时间事件处理函数
aeTimeProc *timeProc;
// 时间事件终结函数
aeEventFinalizerProc *finalizerProc;
// 客户端传入的数据
void *clientData;
// 指向下一个时间事件
struct aeTimeEvent *next;
} aeTimeEvent; //时间事件
/* State of an event based program */
typedef struct aeEventLoop {
// 当前已注册的最大的文件描述符
int maxfd; /* highest file descriptor currently registered */
// 文件描述符监听集合的大小
int setsize; /* max number of file descriptors tracked */
// 下一个时间事件的ID
long long timeEventNextId;
// 最后一次执行事件的时间
time_t lastTime; /* Used to detect system clock skew */
// 注册的文件事件表
aeFileEvent *events; /* Registered events */
// 已就绪的文件事件表
aeFiredEvent *fired; /* Fired events */
// 时间事件的头节点指针
aeTimeEvent *timeEventHead;
// 事件处理开关
int stop;
// 多路复用库的事件状态数据
void *apidata; /* This is used for polling API specific data */
// 执行处理事件之前的函数
aeBeforeSleepProc *beforesleep;
} aeEventLoop; //事件轮询的状态结构
// 事件轮询的主函数
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
// 一直处理事件
while (!eventLoop->stop) {
// 执行处理事件之前的函数
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
//处理到时的时间事件和就绪的文件事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
- aeProcessEvents(eventLoop, AE_ALL_EVENTS); 核心逻辑:
- 查找最早的时间事件,判断是否需要执行,如需要,就标记下来,等待处理
- 获取已准备好的文件事件描述符集
- 优先处理读事件
- 处理写事件
- 如有时间事件,就处理时间事件
第三部分: 内部数据结构源码分析;
SDS(Simple Dynamic String)
- sds 代替了C默认的
char*类型,因为char功能单一,抽象层次低,并且不能高效地支持一些Redis常见操作,比如 追加操作和长度计算,所以在redis内部,大多数使用sds而不是char表示字符串; - 在C中,字符串以
\0结尾的char数组来表示,缺点是,每次计算字符串的长度(strlen(s))复杂度O(n); 对字符串进行N次追加,必定需要对字符串进行N次内存重分配(realloc); 由于对字符串的追加APPEND和长度计算STRLEN 操作很频繁,所以不应该成为性能瓶颈。以及Redis字符串还应该是二进制安全的数据可以以任意结尾不一定就是\0; 归结以上原因所以替换了C默认的char*;
#define SDS_MAX_PREALLOC (1024*1024) //预先分配内存的最大长度1MB
typedef char *sds; //sds兼容传统C风格字符串,所以起了个别名叫sds,并且可以存放sdshdr结构buf成员的地址
struct sdshdr {
unsigned int len; //buf中已占用空间的长度
unsigned int free; //buf中剩余可用空间的长度,惰性释放,在做释放操作时并不会马上减少SDS所占内存,而是free增加,同时对外提供真正释放的API,被调用时才真正释放
char buf[]; //初始化sds分配的数据空间
};
//举例
struct sdshdr {
len = 11; // O(1) 计算长度
free = 0;
buf = "hello world\0"; //buf 实际长度为len+1
}
//当操作 `append msg " again!"` 则
struct sdshdr {
len = 18;
free = 18; // 这里做了扩容操作,小于SDS_MAX_PREALLOC则2倍扩容否则分配SDS_MAX_PREALLOC大小;
buf = "hello world again!\0";
}
- 扩容逻辑
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
size_t free = sdsavail(s); //获得s的未使用空间长度
size_t len, newlen;
if (free >= addlen) return s; //free的长度够用不用扩展直接返回
//free长度不够用,需要扩展
len = sdslen(s); //获得s字符串的长度
sh = (void*) (s-(sizeof(struct sdshdr)));
newlen = (len+addlen); //扩展后的新长度
if (newlen < SDS_MAX_PREALLOC) //新长度小于“最大预分配长度”,就直接将扩展的新长度乘2
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //新长度大于“最大预分配长度”,就在加上一个“最大预分配长度”
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); //获得新的扩展空间的地址
if (newsh == NULL) return NULL;
newsh->free = newlen - len; //更新新空间的未使用的空间free
return newsh->buf;
}
小结:
- Redis字符串表示为sds,不是C字符串以
\0结尾的char*; - sds做了如下改进
-
- 高效执行长度计算(strlen)
-
- 高效进行追加操作(append)
-
- 二进制安全? 怎么理解,简单讲不以任何特殊格式为结尾就是二进制安全的,比如C以
\0就不是二进制安全的。
- 二进制安全? 怎么理解,简单讲不以任何特殊格式为结尾就是二进制安全的,比如C以
- 二进制安全 wiki-binary-safe
- sds可能会在做APPEND操作时进行扩容操作,从而加快追加操作速度,并降低内存分配次数,代价时多占用了些内存。
双端链表
- 操作:RPUSH, LPOP, LLEN…
- Redis列表使用两种数据结构作为底层实现;1. 双端链表 2. 压缩列表; 由于双端链表占用的内存比压缩列表要多, 所以当创建新的列表键时,列表会优先考虑使用压缩列表作为底层实现,并且在有需要的时候,才从压缩列表实现转换到 双端链表实现。
- 除了实现列表类型以外,双端链表还被很多 Redis 内部模块所应用:
• 事务模块使用双端链表来按顺序保存输入的命令;
• 服务器模块使用双端链表来保存多个客户端;
• 订阅/发送模块使用双端链表来保存订阅模式的多个客户端;
• 事件模块使用双端链表来保存时间事件(time event)
- 具体数据结构,以及对应的特点
typedef struct listNode {
struct listNode *prev; //前驱节点,如果是list的头结点,则prev指向NULL
struct listNode *next; //后继节点,如果是list尾部结点,则next指向NULL
void *value; //万能指针,能够存放任何信息 ⚠️
} listNode;
typedef struct listIter {
listNode *next; //迭代器当前指向的节点(名字叫next有点迷惑)
int direction; //迭代方向,可以取以下两个值:AL_START_HEAD和AL_START_TAIL
} listIter;
typedef struct list {
listNode *head; //链表头结点指针
listNode *tail; //链表尾结点指针
//下面的三个函数指针就像类中的成员函数一样
void *(*dup)(void *ptr); //复制链表节点保存的值
void (*free)(void *ptr); //释放链表节点保存的值
int (*match)(void *ptr, void *key); //比较链表节点所保存的节点值和另一个输入的值是否相等
unsigned long len; //链表长度计数器 时间复杂度O(1)
} list;
字典 dictionary
typedef struct dictEntry {
void *key; //key
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; //value
struct dictEntry *next; //指向下一个hash节点,用来解决hash键冲突(collision)
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //计算hash值的函数
void *(*keyDup)(void *privdata, const void *key); //复制key的函数
void *(*valDup)(void *privdata, const void *obj); //复制value的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);//比较key的函数
void (*keyDestructor)(void *privdata, void *key); //销毁key的析构函数
void (*valDestructor)(void *privdata, void *obj); //销毁val的析构函数
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht { //哈希表
dictEntry **table; //存放一个数组的地址,数组存放着哈希表节点dictEntry的地址。
unsigned long size; //哈希表table的大小
unsigned long sizemask; //用于将哈希值映射到table的位置索引。它的值总是等于(size-1)。
unsigned long used; //记录哈希表已有的节点(键值对)数量。
} dictht;
typedef struct dict {
dictType *type; //指向dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据。
void *privdata; //私有数据,保存着dictType结构中函数的参数。
dictht ht[2]; //两张哈希表。只是用ht[0],当发生rehash时,ht[1]才被使用;
long rehashidx; //rehash的标记,rehashidx==-1,表示没在进行rehash
int iterators; //正在迭代的迭代器数量
} dict;
Rehash 触发条件与渐进式 Rehash 机制
触发条件:Redis 通过负载因子 ratio = used / size 判断是否需要 rehash:
- 自然 rehash:
ratio >= 1且dict_can_resize = true(默认为真)。当 Redis 执行 BGSAVE 或 BGREWRITEAOF 时,为利用 copy-on-write 机制会将dict_can_resize设为 false,避免此时触发 rehash - 强制 rehash:
ratio > dict_force_resize_ratio(默认值 5),即使有后台持久化任务也会强制执行
渐进式 Rehash 过程:
- 为
ht[1]分配空间(扩容时为>= used * 2的最小 2^n,缩容时为>= used的最小 2^n) - 将
rehashidx设为 0,标记 rehash 开始 - 每次对字典执行 CRUD 操作时,顺带将
ht[0]在rehashidx位置的所有键值对迁移到ht[1],完成后rehashidx++ - 期间查询先查
ht[0]再查ht[1],新增只写入ht[1] - 全部迁移完成后,释放
ht[0],将ht[1]设为ht[0],新建空ht[1],rehashidx设为 -1
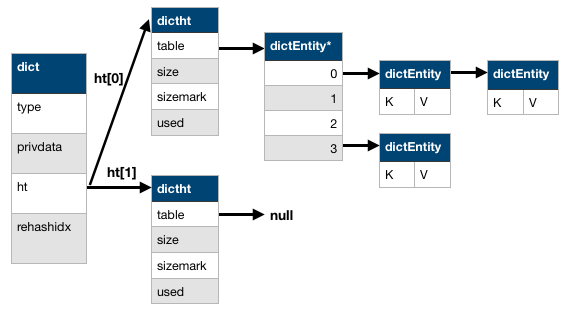
核心流程
- 计算key的hash值,找到hash映射到table数组的下标。
- 如果key已经存在,则hash碰撞,链表处理,头插。
- 如果key多次发生碰撞,链表将越来越长,查询速度越来越慢,为了维持正常的负载,Redis将会进行
渐进式rehash操作,增加table数组长度。步骤如下:-
- 根据ht[0]的数据和操作的类型(扩容/缩小),分配ht[1]大小,并修改rehashidx值
-
- 将ht[0]的数据rehash到ht[1]上
-
- rehash完成以后,将ht[1]设置为ht[0],并生成一个新的ht[1]以备下次使用
-
- 考虑到key数量可能千万级别,一次rehash将会是一个相对较长的时间,所以为了在rehash期间能继续对外提供服务,Redis采用渐进式rehash.
-
- 分配ht[1]空间,字典同时持有ht[0]和ht[1].
-
- 在字典中维护一个rehashidx,设置为0,表示字典正在进行rehash操作。
-
- 在rehash期间,每次对字典的操作除了进行指定的操作外,都会根据ht[0]的在rehashidx上对应的键值对rehash到ht[1]
-
- 随着多次操作ht[0]的数据将会全部rehash到ht[1]上,设置ht[0]的rehashidx=-1表示rehash过程结束
-
- 在进行rehash过程中,如果进行了delete和update等操作,会在两个哈希表上进行,如果是查询则优先在ht[0]上积习难改,如果没有,再去ht[1]中查找。如果是insert则只会在ht[1]中插入数据,这样保证了ht[1]的数据只增不减,ht[0]的数据不增。
思考: 1. rehash触发有哪些情况? 3. 如果扩容的时候,rehash还未结束,有发生了rehash会怎么样?
rehash触发条件
每次添加新的K/V之前,将会对哈希表进行检查,ratio=used/size满足以下任何一个条件,rehash过程被触发:
- 自然rehash: ratio >= 1,且dict_can_resize=true,默认为1即,为真;注意: 当Redis使用子进程对数据库执行后台持久化任务时,比如BGSAVE或BGREWRITEAOF时,为最大化利用系统的copy on write 机制,则将dict_can_resize修改为假,避免执行自然rehash,提高性能,当持久化任务完成将恢复为真。当满足强制rehash条件,即时dict_can_resize不为真,有BGSAVE或BGREWRITEAOF正执行,这个字典一样被进行rehash操作。
- 强制rehash: ratio > dict_force_resize_ration(默认5)
- dictRehashMilliseconds 可以在指定的毫秒数内,对字典进行 rehash 。可以加速整体rehash速度。
- 当哈希表大小大于DICT_HT_INITIAL_SIZE(默认4),且(used/size)小于10%将进行
缩容,释放内存空间。思考: 渐进式rehash,是一种分散集中处理数据迁移的思路。
跳表 skiplist

- 表头: 维护跳表的节点指针
- 跳表节点: 保存元素,以及多个层
- 层: 保存指向其它元素的指针。搞成的指针越过的元素数量大于等于底层指针,为了提高查询效率,程序总先从高层开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾: 全部由NULL组成,表示跳跃表的末尾
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//header指向跳跃表的表头节点,tail指向跳跃表的表尾节点
unsigned long length;//跳跃表的长度或跳跃表节点数量计数器,除去第一个节点
int level;//跳跃表中节点的最大层数,除了第一个节点
} zskiplist;
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj; //保存成员对象的地址
double score;//分值
struct zskiplistNode *backward;//后退指针
struct zskiplistLevel {
struct zskiplistNode *forward;//前进指针
unsigned int span;//跨度
} level[];//层级,柔型数组
} zskiplistNode;
- 跳表的应用主要是实现有序数据类型,是一种随机化数据结构,它的查找,添加,删除操作都可以在对数期间完成。 为适应Redis自身需求,作者作出如下修改1. score值可重复。 2. 对比一个元素需要同时检查它的score和member。 3. 每个节点带有高度为1层的后退指针,用于从表尾方向向表头方向迭代。
Redis内存映射数据结构
- 内存映射数据结构是一系列经过特殊编码的字节序列。创建它们所消耗的内存通常比作用类似的内部数据结构要少得多,若果使用得当,内存映射数据结构可以为用户节约大量内存。不过,内存映射数据结构的编码和操作方式比内部数据结构要复杂得多,所以内存映射数据结构占用CPU时间会比作用类似的内部数据结构要多。
整数集合 intset
- 用于有序,无重复地保存多个整数值,它会根据元素的值,自动选择该用什么长度的整数类型来保存元素。
- 当一个位长度更长的整数值添加到intset时,需要对intset进行升级,新intset中每个元素的位长度都等于新添加值的位长度比如从32->64,但原有元素的值不变。
- 升级会引起整个intset进行内存重分配,并移动集合中的所有元素,这个操作的复杂度O(N)
- intset只支持升级不支持降级
- intset为有序的,采用二分查找算法实现查找,复杂度O(lgN)
压缩列表 ziplist
- ziplist可以包含多个节点(entry),每个节点可以保存一个长度受限的字符数组。
- TODO 好好研究以下
Redis数据类型
- 核心结构体redisObject
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; //编码方式
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount; // 引用计数
void *ptr; //指向保存对象的地址
} robj;
//type对象类型
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
//对象编码
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
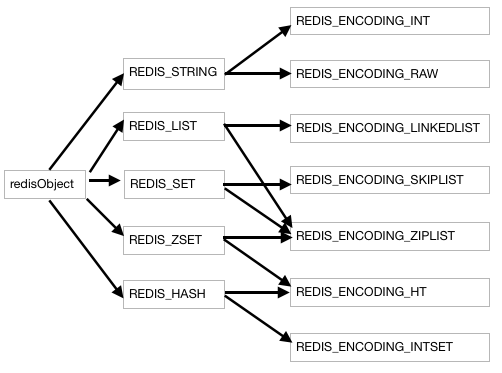
Redis处理数据时的核心逻辑
- 根据给定的key,在数据字典中查找到redisObject,如果没有返回NULL
- 检查redisObject和type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误
- 根据redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构
- 返回数据结构的操作结果作为命令的返回值
Redis对象共享
- Flyweight模式预先分配一些常见的额值对象,并在多个数据结构之间共享这些对象,节约内存空间以及CPU时间。预分配的值对象如下:
-
- 各种命令的返回值,比如执行成功时返回的OK,执行错误时返回的ERROR,类型错误返回WRONGTYPE等等
-
- 包括0在内,小于REDIS_SHARED_INTEGERS 10000的所有整数
- 注意:共享对象只能被带指针的数据结构使用,比如字典,双端链表这类数据结构。比如整数集合和压缩链表这些只能保存字符串,整数字面值的内存数据结构,不能使用共享对象。
Redis引用计数以及对象的销毁,运行机制如下:
- 每个redisObject结构都有一个refcount属性,指示这个对象被引用了多少次。当创建一个对象时,refcount=1
- 当对一个对象进行共享时,refcount++; 使用完或者取消共享引用时,将对象refcount–;当refcount=0时,这个redisObject结构以及它所应用的数据结构的内存都将被销毁释放。
字符串
- 字符串类型分别使用 REDIS_ENCODING_INT 和 REDIS_ENCODING_RAW(默认编码) 两种编码:
• REDIS_ENCODING_INT 使用 long 类型来保存 long 类型值。
• REDIS_ENCODING_RAW 则使用 sdshdr 结构来保存 sds (也即是 char* )、long long 、 double 和 long double 类型值。
哈希表
- REDIS_HASH使用REDIS_ENCODING_ZIPLIST(默认编码)和 REDIS_ENCODING_HT 两种编码方式。当满足以下情况,将被切换到REDIS_ENCODING_HT编码:
-
- 哈希表中某个键或某个值长度大于server.hash_max_ziplist_value(默认64)
-
- 压缩列表中节点数量大于server.hash_max_ziplist_entries(默认512)
思考为什么满足如上提交则切换编码格式? 主要时过长和节点过多时其综合性能低下?
列表 REDIS__LIST
- 压缩列表中节点数量大于server.hash_max_ziplist_entries(默认512)
- 使用REDIS_ENCODING_ZIPLIST(默认编码) 和 REDIS_ENCODING_LINKEDLIST 这两种方式编码; 编码切换场景与哈希表一样。
- 阻塞队列
集合 REDIS_SET
- REDIS_ENCODING_INTSET 和 REDIS_ENCODING_HT 两种方式编码; 如果第一个元素可以表示为long则采用INTSET编码否则HT; 当INTSET编码保存的整数个数超过512个也发生编码切换HT,或者试图填入不是非long类型元素,也发生编码切换。
有序集合 REDIS_ZSET
- REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_SKIPLIST 两种方式编码;第一个添加的元素满足以下条件则创建一个REDIS_ENCODING_ZIPLIST;
- 服务器属性server.zset_max_ziplist_entries的值大于0(默认为128)
- 元素的member长度小于服务器属性server.zset_max_ziplist_value的值(默认为64)
功能实现
事务
MULTI, DISCARD,EXEC,WATCH四个命令实现事务MULTI:命令的作用就是将客户单的REDIS_MULTI选项打开,让客户端从非事务状态切换到事务状态,当客户端处于非事务状态下,所有发送给服务器端的命令都会立即被服务器执行。但是当进入事务状态,服务器在收到来自客户端命令时,不会立即执行命令,而是将这些命令全部放进一个事务队列里,然后返回QUEUED,表示命令已经入队。事务队列是一个数组,每个数组项都是包含了三个属性:1. 要执行的命令(CMD) 2. 命令的参数(argv) 3. 参数的个数(argc) 举例:
redis> MULTI
OK
redis> set book "C++"
QUEUED
redis> get book
QUEUED
redis> set book "Golang"
QUEUED
| 数组索引 | cmd | argv | argc |
|---|---|---|---|
| 0 | set | [“book”, “C++”] | 2 |
| 1 | get | [“book”] | 1 |
| 2 | set | [“book”, “Golang”] | 2 |
- 注意⚠️并不是所有客户端的命令都被放到事务队列中,比如
EXEC,DISCARD,MULTI,WATCH将被立即执行;事务回复就是创建一个空白回复队列,取出事务队列里面所有命令,执行并取得返回值,将返回值入队到回复队列,清除掉客户端的事务状态,清空事务队列,将事务结果返回给客户端。⚠️事务执行时服务器不会中断事务,也不会回滚。 - 对于WATCH的触发,将会有一个watched_keys字典,只要有被其它client修改字典中的key值,则对应的client的
REDIS_DIRTY_CAS选项被打开,那么在当前client端执行EXEC时受限检查REDIS__DIRTY_CAS是否被破坏,如果是返回错误并清空事务队列,否则执行事务。举例:
| watched_keys | watch的客户端 |
|---|---|
| key1 | client2 –> client3 —> client4….. |
| key2 | client6 |
| key3 | client5 |
-
如果某个客户端对key1进行了修改比如del key1, 那么所有监视key1的客户端,包括client2,client3,client4的
REDIS_DIRTY_CAS选项都被打开,当client2,3,4执行EXEC时,它们的事务都将失败。最后当一个客户单结束它的事务时无论事务执行成功失败watched_keys字典中和这个客户端的资料都会被清除。 原子性:单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。 如果一个事务队列中的所有命令都被成功地执行,那么称这个事务执行成功。 另一方面,如果 Redis 服务器进程在执行事务的过程中被停止——比如接到 KILL 信号、宿主 机器停机,等等,那么事务执行失败.当事务失败时,Redis 也不会进行任何的重试或者回滚动作。一致性:三个部分,入队错误,执行错误,Redis进行被终结- 入队错误,如果发生了入队错误,服务器向客户端返回一个出错信息,并且将客户端的事务状态设为
REDIS_DIRTY_EXEC,所以不正确的入队命令不会执行不会影响一致性 - 执行错误:如果命令在事务执行的过程中发生错误,比如说,对一个不同类型的 key 执行了错误的操作, 那么 Redis 只会将错误包含在事务的结果中,这不会引起事务中断或整个失败,不会影响已执 行事务命令的结果,也不会影响后面要执行的事务命令,所以它对事务的一致性也没有影响。
- 入队错误,如果发生了入队错误,服务器向客户端返回一个出错信息,并且将客户端的事务状态设为
3 . 进程被终结
当Redis进程处理事务中被强制终结,那么Redis会根据其所采取的持久化模式,产生不同的结果,如下:
| 模式 | 措施 |
|---|---|
| 内存模式 | 如果没有采用任何持久化机制,数据库重启总时空的,所以数据总是一致的。 |
| RDB模式 | 在执行事务时,Redis 不会中断事务去执行保存 RDB 的工作,只有在事务执 行之后,保存 RDB 的工作才有可能开始。所以当 RDB 模式下的 Redis 服务器进程在事 务中途被杀死时,事务内执行的命令,不管成功了多少,都不会被保存到 RDB 文件里。 恢复数据库需要使用现有的 RDB 文件,而这个 RDB 文件的数据保存的是最近一次的数 据库快照(snapshot),所以它的数据可能不是最新的,但只要 RDB 文件本身没有因为 其他问题而出错,那么还原后的数据库就是一致的。 |
| AOF模式 | 因为保存 AOF 文件的工作在后台线程进行,所以即使是在事务执行的中途, 保存 AOF 文件的工作也可以继续进行,因此,根据事务语句是否被写入并保存到 AOF 文件,有以下两种情况发生:1)如果事务语句未写入到 AOF 文件,或 AOF 未被 SYNC 调用保存到磁盘,那么当进 程被杀死之后,Redis 可以根据最近一次成功保存到磁盘的 AOF 文件来还原数据库,只 要 AOF 文件本身没有因为其他问题而出错,那么还原后的数据库总是一致的,但其中的 数据不一定是最新的。2)如果事务的部分语句被写入到 AOF 文件,并且 AOF 文件被成功保存,那么不完整的 事务执行信息就会遗留在 AOF 文件里,当重启 Redis 时,程序会检测到 AOF 文件并不 完整,Redis 会退出,并报告错误。需要使用redis-check-aof 工具将部分成功的事务命令 移除之后,才能再次启动服务器。还原之后的数据总是一致的,而且数据也是最新的(直 到事务执行之前为止)。 |
隔离性: Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执 行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。持久性: 因为事务不过是用队列包裹起了一组 Redis 命令,并没有提供任何额外的持久性功能,所以事 务的持久性由 Redis 所使用的持久化模式决定:在单纯的内存模式下,事务肯定是不持久的。在 RDB 模式下,服务器可能在事务执行之后、RDB 文件更新之前的这段时间失败,所以 RDB 模式下的 Redis 事务也是不持久的。在 AOF 的“总是 SYNC ”模式下,事务的每条命令在执行成功之后,都会立即调用 fsync或 fdatasync 将事务数据写入到 AOF 文件。但是,这种保存是由后台线程进行的,线程不会阻塞直到保存成功,所以从命令执行成功到数据保存到硬盘之间,还是有一段非常小的间隔,所以这种模式下的事务也是不持久的。其他 AOF 模式也和“总是 SYNC ”模式类似,所以它们都是不持久的。- Redis事务保证了ACID中的一致性,隔离性(单线程)并不保证原子性和持久性
订阅与发布
- 命令:
SUBSCRIBE channel订阅频道,PUBLISH channel message向频道发送消息,PSUBSCRIBE pattern按模式(支持glob风格通配符)订阅频道。对应的退订命令为UNSUBSCRIBE和PUNSUBSCRIBE。 - 底层数据结构:服务器状态
redisServer中维护了pubsub_channels字典和pubsub_patterns链表。pubsub_channels的键是频道名,值是订阅该频道的客户端链表;pubsub_patterns是一个链表,每个节点保存了客户端指针和其订阅的模式字符串。 - 频道订阅 vs 模式订阅:频道订阅是精确匹配,客户端只接收指定频道的消息;模式订阅使用通配符匹配(如
news.*),客户端会接收所有匹配该模式的频道消息。两者可以同时使用,同一条消息可能被客户端收到多次(一次来自频道订阅,一次来自模式订阅)。 - 消息广播机制:当执行
PUBLISH channel message时,服务器首先在pubsub_channels字典中查找该频道,将消息发送给所有订阅了该频道的客户端;然后遍历pubsub_patterns链表,将消息发送给所有匹配该频道名的模式订阅客户端。整个过程时间复杂度为 O(N+M),N是频道订阅者数量,M是模式订阅总数。
Lua脚本
- 命令:
EVAL script numkeys key [key ...] arg [arg ...]直接执行Lua脚本,EVALSHA sha1 numkeys key [key ...]通过SHA1校验和执行已缓存的脚本。SCRIPT LOAD可以预先将脚本载入缓存而不执行。 - 内嵌Lua解释器:Redis内嵌了一个Lua 5.1解释器,服务器启动时创建Lua环境并加载基础库(如
string、math、table等),同时移除可能产生副作用的函数(如loadfile),确保脚本执行的安全性和确定性。 - 脚本缓存与SHA1:每个通过
EVAL执行的脚本都会以其SHA1校验和为键缓存在服务器的lua_scripts字典中。后续可以通过EVALSHA直接引用已缓存的脚本,避免重复传输脚本内容,节约网络带宽。SCRIPT EXISTS可检查脚本是否已被缓存,SCRIPT FLUSH清空脚本缓存。 - 原子执行:Lua脚本在Redis中以原子方式执行,脚本执行期间服务器不会处理其他客户端的命令请求(类似于事务的隔离性),因此脚本中的多个Redis操作天然具有原子性。但要注意脚本不应执行过长时间,否则会阻塞整个服务器,可通过
lua-time-limit配置超时时间。 - redis.call() vs redis.pcall():在Lua脚本中通过
redis.call()和redis.pcall()调用Redis命令。两者的区别在于错误处理:redis.call()在命令执行出错时会直接抛出Lua错误,终止脚本执行并向客户端返回错误;redis.pcall()则会捕获错误并返回一个包含错误信息的Lua table,脚本可以自行决定如何处理错误,继续执行后续逻辑。慢查询日志
- slowlog.h/slowlogEntry定义
- Redis用一个
链表以FIFO的顺序保存着所有慢查询日志,每条慢查询日志以一个慢查询节点表示,节点中记录着执行超时的命令,命令的参数,命令执行时的时间等信息。
内部运作机制
数据库
- 过期清除:1. 定时清除,占用CPU时间严重 2. 惰性情怀,取键时判断是否过期,浪费内存空间 3. 定期删除1,2策略的折中方案
- REDIS使用的淘汰策略
过期键删除策略和惰性删除策略加上定期删除合理利用CPU时间以及节约内存.
第四部分: 分布式锁,事务,持久化;
分布式锁
- SETNX + EXPIRE(旧模式):早期实现分布式锁的方式是先用
SETNX key value设置锁(仅当key不存在时设置成功),再用EXPIRE key timeout设置过期时间防止死锁。但这两个操作不是原子的——如果客户端在SETNX成功后、EXPIRE执行前崩溃,锁将永远不会被释放,导致死锁。 - SET key value NX PX(原子操作):Redis 2.6.12+ 支持
SET key value NX PX milliseconds将加锁和设置过期时间合并为一个原子操作,解决了旧模式的非原子性问题。value 通常设为一个随机UUID,释放锁时通过Lua脚本先比较value再删除,确保只有持有锁的客户端才能释放锁(避免误删其他客户端的锁)。 - Redlock 算法:由Redis作者Antirez提出,用于在多个独立Redis实例上实现更可靠的分布式锁。客户端依次向N个(通常5个)独立的Redis节点请求加锁,如果在大多数节点(N/2+1)上加锁成功,且获取锁的总耗时小于锁的有效期,则认为加锁成功。锁的实际有效时间 = 初始有效期 - 获取锁耗时。释放锁时向所有节点发送释放命令。Redlock在一定程度上解决了单点故障问题,但Martin Kleppmann等人指出其在网络分区和时钟漂移等场景下仍存在安全性问题。
- 锁续期(Watchdog机制):在实际应用中(如Redisson),为了防止业务逻辑执行时间超过锁的过期时间导致锁提前释放,引入了看门狗(Watchdog)机制。客户端获取锁后,后台线程会定期(通常每隔过期时间的1/3)检查锁是否仍被持有,如果是则自动续期。当客户端主动释放锁或客户端宕机(看门狗线程也随之终止)时,锁最终会因过期而自动释放。
持久化
RDB(Redis Database)
- 工作原理:RDB是Redis的数据快照持久化方式,在某个时间点将内存中的全部数据生成快照并写入磁盘上的二进制文件(dump.rdb)。可通过
SAVE(阻塞主线程)或BGSAVE(fork子进程后台执行)触发。 - BGSAVE fork机制:执行
BGSAVE时,Redis通过fork()系统调用创建子进程。子进程共享父进程的内存页面(copy-on-write),在子进程生成RDB文件的过程中,父进程继续处理客户端请求。只有当父进程修改了某个内存页时,操作系统才会复制该页,因此内存开销通常远小于全量数据。 - 自动触发:通过配置
save <seconds> <changes>设置自动快照条件,如save 900 1表示900秒内至少1次修改则触发BGSAVE。Redis会通过serverCron定时函数检查这些条件。 - 优缺点:RDB文件紧凑,适合备份和灾难恢复,加载速度快于AOF;缺点是两次快照之间的数据可能丢失,且fork大内存实例时可能造成短暂的服务停顿。
AOF(Append Only File)
- 工作原理:AOF以追加的方式记录Redis执行的每一条写命令,以Redis协议格式保存在AOF文件中。恢复数据时,Redis重新执行AOF文件中的所有命令来重建数据集。
- fsync策略:AOF提供三种同步策略,通过
appendfsync配置:always:每条写命令执行后立即fsync,数据安全性最高但性能最差everysec(默认推荐):每秒fsync一次,最多丢失1秒数据,性能与安全的平衡no:由操作系统决定何时fsync,性能最好但数据丢失风险最大(Linux通常30秒刷盘一次)
- AOF重写(BGREWRITEAOF):随着运行时间增长,AOF文件会越来越大。AOF重写通过fork子进程,根据当前内存数据直接生成最精简的命令集(而非读取旧AOF文件),从而大幅缩小AOF文件体积。重写期间父进程将新的写命令同时写入AOF缓冲区和AOF重写缓冲区,子进程完成重写后,父进程将重写缓冲区的内容追加到新AOF文件末尾,最后原子替换旧文件。
RDB + AOF 混合持久化(Redis 4.0+)
- 通过配置
aof-use-rdb-preamble yes开启。在AOF重写时,子进程先将当前数据以RDB格式写入新AOF文件的开头,然后将重写期间产生的增量命令以AOF格式追加在RDB数据之后。这样既保留了RDB快速加载的优势,又保留了AOF增量记录的优势,是Redis 4.0+推荐的持久化方案。加载时Redis先识别文件头部的RDB格式进行快速加载,再执行后面的AOF命令。
第五部分: Redis集群研究;
主从复制
- SLAVEOF命令:通过
SLAVEOF masterip masterport(Redis 5.0+改为REPLICAOF)将一个Redis实例设为另一个实例的从节点。从节点连接主节点后,首先进行全量同步,之后持续进行增量同步。 - 全量同步(Full Resync):从节点首次连接主节点或无法进行部分同步时触发。主节点执行
BGSAVE生成RDB快照发送给从节点,同时将期间收到的写命令缓存在复制缓冲区中。从节点收到RDB文件后加载到内存,再执行缓冲区中的写命令,最终与主节点数据一致。 - 部分同步(Partial Resync):Redis 2.8+支持
PSYNC命令实现部分重同步。主节点维护一个固定大小的复制积压缓冲区(replication backlog,默认1MB),记录最近传播的写命令。每个主从节点都维护一个复制偏移量(replication offset)。当从节点短暂断线后重连,如果断线期间的数据仍在积压缓冲区中(即从节点的offset在缓冲区范围内),则只需发送缺失的部分数据(部分同步),避免全量同步的开销。 - PSYNC流程:从节点发送
PSYNC <runid> <offset>,主节点根据runid判断是否是自己的从节点,再根据offset判断能否进行部分同步。如果runid不匹配或offset对应的数据已不在积压缓冲区中,则回退到全量同步。
Redis Sentinel(哨兵)
- 监控(Monitoring):Sentinel以每秒一次的频率向主节点、从节点和其他Sentinel实例发送
PING命令,检测实例是否在线。当一个实例在down-after-milliseconds配置的时间内未回复,该Sentinel将其标记为主观下线(SDOWN)。 - 自动故障转移(Automatic Failover):当足够多的Sentinel(达到
quorum配置数量)都将主节点标记为主观下线时,主节点被标记为客观下线(ODOWN)。此时Sentinel通过Raft协议选举出一个领头Sentinel,由其执行故障转移:从从节点中选择一个提升为新主节点(优先级 > 复制偏移量 > runid),让其他从节点复制新主节点,并更新配置。 - 通知(Notification):Sentinel充当客户端的通知中心,当被监控的Redis实例发生故障转移时,Sentinel通过发布/订阅机制通知客户端新主节点的地址。客户端可以订阅Sentinel的频道来获取实时事件通知。
- 配置提供者(Configuration Provider):客户端连接Sentinel而非直接连接Redis主节点。客户端向Sentinel查询当前主节点地址,Sentinel返回最新的主节点信息。当故障转移发生时,客户端能够通过Sentinel自动发现新的主节点地址,实现高可用。
Redis Cluster(集群)
- 16384哈希槽(Hash Slots):Redis Cluster将整个数据空间划分为16384个哈希槽。每个key通过
CRC16(key) % 16384计算所属槽位,每个节点负责一部分槽位。使用16384而非更大数值是为了保证节点间心跳包中的槽位bitmap不至于过大(16384 bits = 2KB)。 - MOVED与ASK重定向:当客户端向节点发送命令,而key所在的槽不由该节点负责时,节点返回
MOVED <slot> <ip>:<port>重定向,客户端应更新本地槽位映射缓存并重新发送请求。ASK重定向发生在槽位迁移过程中,表示该槽正在从源节点迁移到目标节点,客户端应临时向目标节点发送命令(先发ASKING再发实际命令),但不更新本地缓存。 - Gossip协议:集群节点通过Gossip协议(PING/PONG消息)交换状态信息,包括节点的负责槽位、在线状态、故障标记等。每个节点每秒随机选取几个节点发送PING消息,收到的节点回复PONG。这种去中心化的方式实现了集群状态的最终一致性,但信息传播存在一定延迟。
- 集群内主从:Redis Cluster支持在集群内为每个主节点配置从节点。当某个主节点故障时,其从节点通过集群内的选举机制(类似Sentinel的故障转移,但由集群节点投票完成)自动提升为新主节点,保证集群的高可用性。集群要求超过半数主节点存活且每个槽位有节点负责,否则集群进入fail状态停止对外服务。
- Resharding(重新分片):通过
redis-cli --cluster reshard或CLUSTER SETSLOT等命令将槽位从一个节点迁移到另一个节点。迁移过程中,源节点将被迁移槽中的key逐个通过MIGRATE命令发送到目标节点。迁移期间该槽的请求可能触发ASK重定向,确保数据访问不中断。
第六部分: Redis整体设计思考, 优缺点分析,是否有更好方案替代?
优点
- 高性能:Redis基于内存操作,配合高效的数据结构和I/O多路复用的单线程模型,单实例可达到10万+ QPS的读写性能。没有磁盘I/O的瓶颈,也没有多线程的上下文切换和锁竞争开销。
- 丰富的数据结构:Redis不仅提供简单的Key-Value存储,还提供String、List、Hash、Set、Sorted Set五种基础数据类型,以及HyperLogLog、Bitmap、Geo、Stream(Redis 5.0+)等扩展类型,能够直接在服务端完成复杂的数据操作(如排序、交并集、排行榜),减少网络往返。
- 单线程模型避免锁竞争:Redis核心命令处理采用单线程,所有操作天然串行化,无需加锁,避免了多线程环境下的锁竞争、死锁和上下文切换等问题,代码简洁且不易出错。(注:Redis 6.0+引入了I/O多线程,但命令执行仍是单线程。)
- 渐进式Rehash:如前文所述,Redis通过渐进式rehash将哈希表扩缩容的大量数据迁移分摊到每次操作中,避免了一次性rehash导致的长时间阻塞,保证了服务的持续可用性。这是一种值得借鉴的”化整为零”的工程设计思想。
缺点
- 内存限制:Redis将所有数据存储在内存中,受限于机器的物理内存大小。虽然可以通过集群分片横向扩展,但单个实例的数据量受内存约束。当数据量远大于内存容量时,需要考虑数据淘汰策略(LRU/LFU/TTL等),且fork子进程执行BGSAVE/BGREWRITEAOF时可能需要额外一倍的内存空间。
- 单线程CPU瓶颈:虽然Redis单线程模型带来了简洁和无锁的优势,但也意味着无法充分利用多核CPU。当遇到CPU密集型操作(如大量Lua脚本计算、大key序列化、
KEYS *等命令)时,单线程将成为性能瓶颈。通常需要通过部署多个Redis实例来利用多核资源。 - 事务不支持回滚:Redis事务(MULTI/EXEC)在命令执行出错时不会回滚已执行的命令,这与传统关系型数据库的事务语义不同。Redis认为事务中的错误通常是编程错误(如类型不匹配),不应该在生产环境中出现,因此为了保持简洁性选择不支持回滚。这要求开发者在使用事务时更加谨慎。
替代方案对比
- Memcached:纯粹的分布式内存缓存系统。优势:多线程模型,天然利用多核CPU;内存分配采用slab机制,减少内存碎片。劣势:仅支持简单的Key-Value(value最大1MB),不支持持久化,不支持复杂数据结构。适合纯缓存场景,对数据结构无要求时可选。
- KeyDB:Redis的多线程分支(由Snap公司维护)。在兼容Redis API的前提下,将网络I/O和命令执行改为多线程模型,充分利用多核CPU,在相同硬件上可获得数倍于Redis的吞吐量。适合对性能有极致要求且希望保持Redis兼容性的场景。
- Dragonfly:新一代内存数据库,声称完全兼容Redis和Memcached协议。采用共享无锁(shared-nothing)架构和多线程设计,在基准测试中吞吐量可达Redis的25倍以上,且内存效率更高。适合需要超高性能且愿意尝试新技术的场景,但社区生态和生产环境验证不如Redis成熟。
- 总结对比:Redis在生态成熟度、功能丰富度和社区支持方面仍是最佳选择。Memcached适合极简缓存需求;KeyDB适合需要Redis兼容但要求更高吞吐量的场景;Dragonfly代表了下一代内存数据库的方向,但仍需更多生产验证。选择时应根据具体业务需求、团队技术栈和运维能力综合考量。