

Zookeeper-V3.4.11
2018-01-05ZookeeperV3.4.11-Doc
- 数据结构+原语+watcher机制(消息通知)
- 问题: 在server挂机时到zookeeper接收到,再到zookeeper通知到client端是有一定的时长的,那么在这段时间内client的服务是不是就丢了?导致全部失败?还是其他什么情况?
- ZooKeeper可以为所有的读操作设置watch,这些读操作包括:exists()、getChildren()及getData()。watch事件是一次性的触发器,当watch的对象状态发生改变时,将会触发此对象上watch所对应的事件。watch事件将被异步地发送给客户端,并且ZooKeeper为watch机制提供了有序的一致性保证。理论上,客户端接收watch事件的时间要快于其看到watch对象状态变化的时间。
ZooKeeper: A Distributed Coordination Service for Distributed Applications
- 功能点同步;配置管理;分组;命名服务。数据结构采用类似目录树的文件系统结构。运行环境Java+C。Zookeeper的愿景就是帮助更容易实现分布式系统
Design Goals
ZooKeeper is simple.每个数据结点称之为znodes,与文件系统不同的是znodes可以做存储,Zookeeper的数据都是在内存中,意味着可以实现高吞吐低延迟- ZooKeeper被设计成高可用,严格顺序执行。可靠性方面意味着不存在单点故障。严格的排序执行意味着在客户端能够做原子操作。
ZooKeeper is replicated.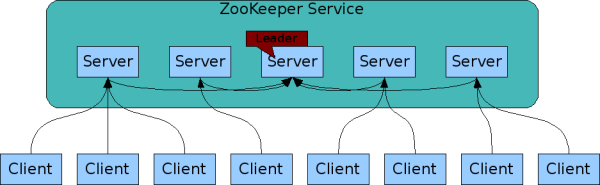 Zookeeper服务之间是相互了解的,通过内存的状态state,以及事务日志和快照做持久存储,只要大部分服务器可用,Zookeeper就是可用的。客户端Client连接到一台ZooKeeper服务器。客户机维护一个TCP连接,通过它sends requests, gets responses, gets watch events, and sends heart beats。如果服务器端的TCP连接断开,客户端将连接到另一个服务器。
Zookeeper服务之间是相互了解的,通过内存的状态state,以及事务日志和快照做持久存储,只要大部分服务器可用,Zookeeper就是可用的。客户端Client连接到一台ZooKeeper服务器。客户机维护一个TCP连接,通过它sends requests, gets responses, gets watch events, and sends heart beats。如果服务器端的TCP连接断开,客户端将连接到另一个服务器。ZooKeeper is ordered.ZooKeeper is fast.,适用于读多写少(最好的比例是,读:写=10:1).读采用就近原则,而写必须都通过Leader来进行排队操作.
Data model and the hierarchical namespace
- 所有的Zookeeper的命名都是确定的通过
/。ZooKeeper’s Hierarchical Namespace如下所示: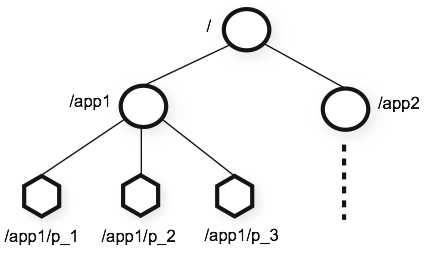
Nodes and ephemeral(临时) nodes
- 就像文件系统一样Zookeeper也是可以有子节点的,每个节点被设计为可以唯一定位的坐标比如 status information, configuration, location information, etc.,所以每个Node通常都是比较小的,通常在千字节以内。节点通常又称为znode.
- Znodes有数据的修改版本,ACL修改,时间戳,允许缓存验证和协调服务的更新。每次数据的修改对应的修改版本属性就会自增,比如客户端接收到的数据也会同时接收到修改版本相关信息。每个数据结点都是读写原子的。每个节点都有一个访问控制列表(ACL)来限制谁可以做什么。
- 临时结点,存在于created znode的session期间,当session结束,znode将被删除。这个可能会有一定延迟,跟zoo.config配置的时间tickTime有关.以及通知到client也会有一定的延迟.
Conditional updates and watches
- Zookeeper的watchs机制,客户端能在一个znodes上面设置一个watch,当znode被修改,移除等操作时,客户端能被通知到znode的改变。当client对应的zoo keeper服务器发生宕机,client将会收到一个notification.
Guarantees
- 顺序一致性-客户端的更新顺序将按其发送的顺序去处理
- 原子性-更新要么成功要么失败,没有其他状态
- Single System Image - A client will see the same view of the service regardless of the server that it connects to.
- 可靠性-更新应用后,将被存留直到下次更改
- 时效性-client看到的数据保证在一定的时间范围内是最新的
- …..tbd
Simple API
reate
creates a node at a location in the tree
delete
deletes a node
exists
tests if a node exists at a location
get data
reads the data from a node
set data
writes data to a node
get children
retrieves a list of children of a node
sync
waits for data to be propagated
...
Implementation
- ZooKeeper Components
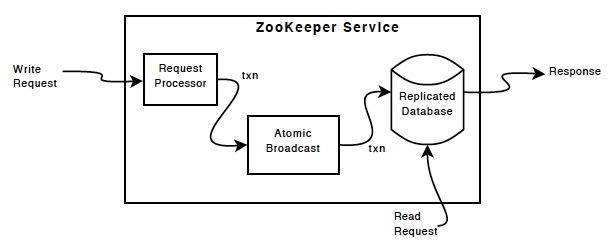 复制的数据库是一个包含整个数据树的内存数据库。更新记录写到磁盘便于恢复数据,写之前将被序列化在内存数据库中。client的读将直接读取最近的service而客户端的所有写操作将被转发给
复制的数据库是一个包含整个数据树的内存数据库。更新记录写到磁盘便于恢复数据,写之前将被序列化在内存数据库中。client的读将直接读取最近的service而客户端的所有写操作将被转发给Leader,而其他的称为followers
Performance
Reliability
ZooKeeper Getting Started Guide
Standalone Operation
- 环境要求JDK必备
- create conf/zoo.cfg
tickTime=2000 //毫秒,心跳时长,最小会话超时时间= 2 * tickTime
dataDir=/var/lib/zookeeper //存储内存数据库快照的位置,除非另有说明,是数据库更新的事务日志。
clientPort=2181 //客户端连接的端口
- 启动 bin/zkServer.sh start
- 默认采用log4j打印日志,这是标准模式,如果是复制模式
Managing ZooKeeper Storage Maintenance
Connecting to ZooKeeper
- $ bin/zkCli.sh -server 127.0.0.1:2181
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
- Test:
ls /create /zk_test my_dataget /zk_testset /zk_test junkdelete /zk_test
TODO Zookeeper 源码分析
Zookeeper 服务注册与发现的问题
总结
- TODO